In this blog, we will use DeepLabv3+ architecture to build our person segmentation pipeline entirely from scratch.

DeepLabv3+ Architecture:
The DeepLabv3 paper was introduced in “Rethinking Atrous Convolution for Semantic Image Segmentation”. After DeepLabv1 and DeepLabv2 are invented, authors tried to RETHINK or restructure the DeepLab architecture and finally come up with a more enhanced DeepLabv3.
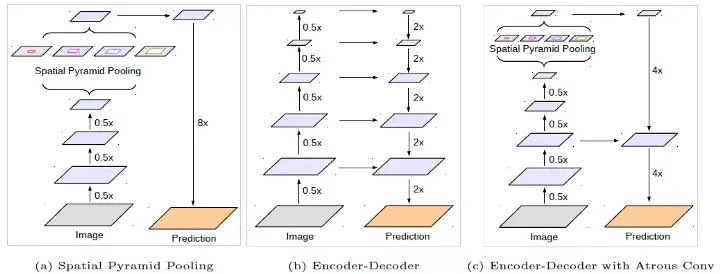
The DeepLabv3+ was introduced in “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation” paper. It combines Atrous Spatial Pyramid Pooling(ASSP) from DeepLabv1(a) and Encoder Decoder Architecture from DeepLabv2(b).

Atrous(Dilated) Convolution:
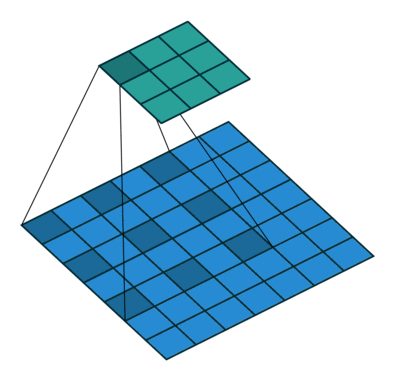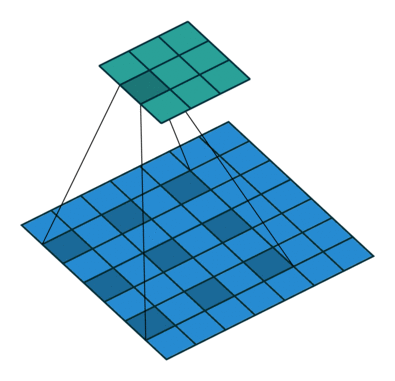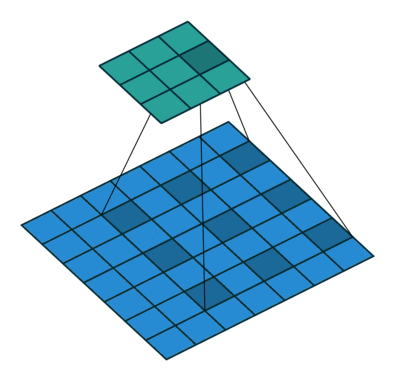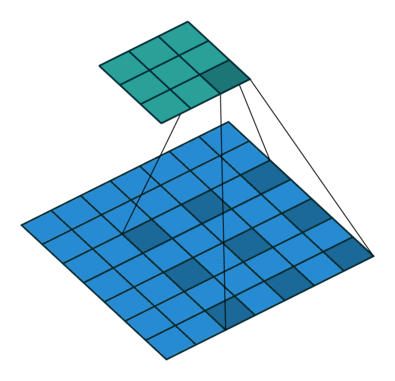
fig 1: 3x3 Atrous(dilated) Convolution in action
Dilated convolutions introduce another parameter to the convolution layers called dilation rate ‘r’. The dilation factor controls the spacing between the kernel points. The convolution performed this way is also known as the à trous algorithm. By controlling the rate parameter, we can arbitrarily control the receptive fields of the convolution layer. The receptive field is defined as the size of the region of the input feature map that produces each output element. This allows the convolution filter to look at larger areas of the input(receptive field) without decreasing the spatial resolution or increasing kernel size.
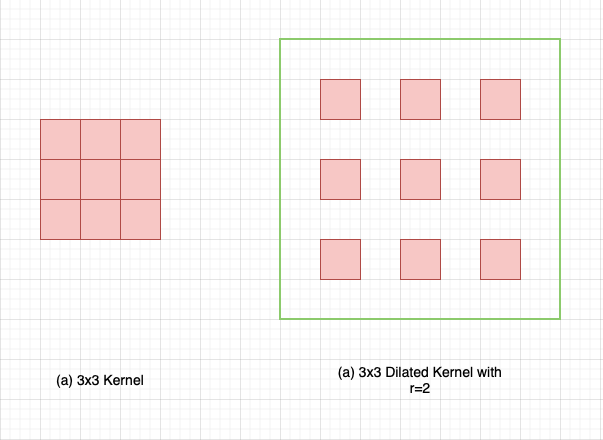
Fig. 1.2: Standard vs Dilated Kernel
Atrous convolution is akin to the standard convolution except that the weights of an atrous convolution kernel are spaced r locations apart, i.e., the kernel of dilated convolution layers is sparse.
The Convolutions and max-pooling used in deep convolutions and the max-pooling layer have disadvantages. At each step, the spatial resolution of the feature map is halved. Implanting or up-sampling the original feature map onto the original images results in sparse feature extraction.
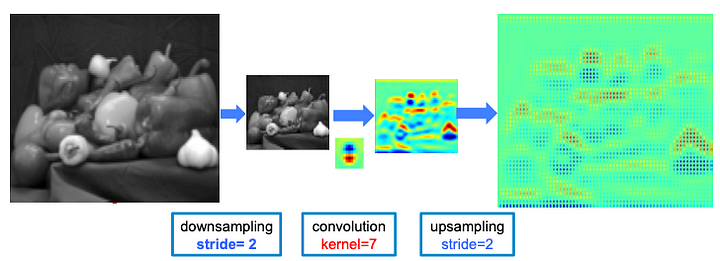
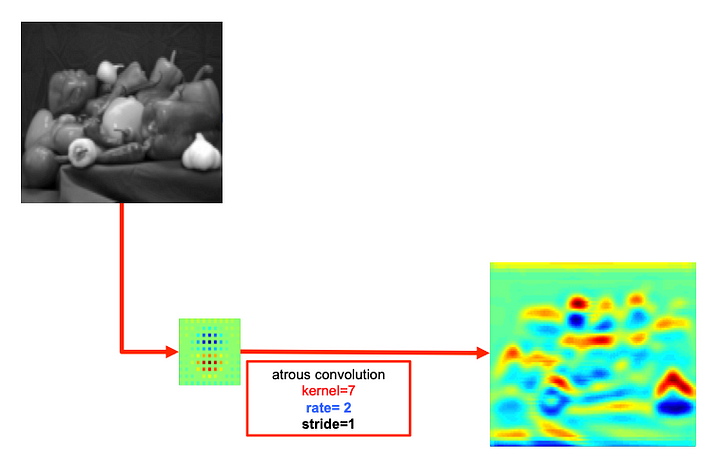
The Atrous convolution allows the convolution filter to look at larger areas of input field without decreasing the spatial resolution or increasing the kernel size.
Let x be the input feature map, y be the output and w be the filter, then atrous convolution for each location i on the output y is :
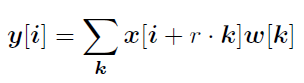
Where r corresponds to the dilation rate. Here, by adjusting r we can control the filter’
s field of view.
Atrous Convolution Block in pytorch:
class Atrous_Convolution(nn.Module):
"""
Compute Atrous/Dilated Convolution.
"""
def __init__(
self, input_channels, kernel_size, pad, dilation_rate,
output_channels=256):
super(Atrous_Convolution, self).__init__()
self.conv = nn.Conv2d(in_channels=input_channels,
out_channels=output_channels,
kernel_size=kernel_size, padding=pad,
dilation=dilation_rate, bias=False)
self.batchnorm = nn.BatchNorm2d(output_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
Encoder:
The Deeplabv3+ uses the Atrous Spatial Pyramid Pooling module, which probes convolution features at multiple scales by applying atrous convolution at different scales by applying atrous convolution with different rates with the image level features.
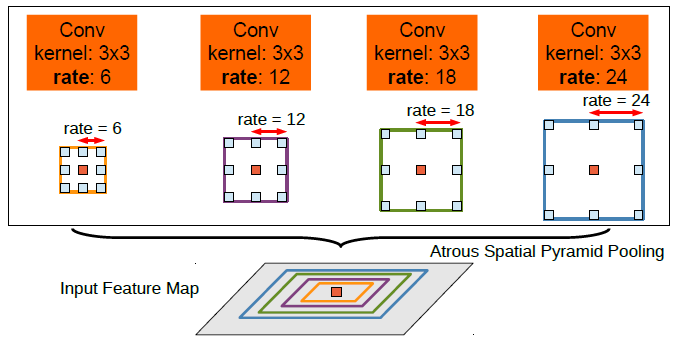
Atrous Spatial Pyramid Pooling (ASPP):
In ASPP, parallel atrous convolution with different rates is applied in the input feature map and fused together. The ASSP enables to encode of multi-scale contextual information, as objects of the same class can have different scales in the image.
In ASPP layer, one 1x1 convolution and three 3x3 convolutions with different rates (3, 6, 18) are applied. Also, an image pooling layer is applied for the global context. All filter layers have 256 filters with batch normalization. All the resulting filters from all the branches are then concatenated and passed through 1x1 convolution which generates the final logits.
Encoder block in pytorch:
class ASSP(nn.Module):
"""
Encoder of DeepLabv3+.
"""
def __init__(self, in_channles, out_channles):
"""Atrous Spatial Pyramid pooling layer
Args:
in_channles (int): No of input channel for Atrous_Convolution.
out_channles (int): No of output channel for Atrous_Convolution.
"""
super(ASSP, self).__init__()
self.conv_1x1 = Atrous_Convolution(
input_channels=in_channles, output_channels=out_channles,
kernel_size=1, pad=0, dilation_rate=1)
self.conv_6x6 = Atrous_Convolution(
input_channels=in_channles, output_channels=out_channles,
kernel_size=3, pad=6, dilation_rate=6)
self.conv_12x12 = Atrous_Convolution(
input_channels=in_channles, output_channels=out_channles,
kernel_size=3, pad=12, dilation_rate=12)
self.conv_18x18 = Atrous_Convolution(
input_channels=in_channles, output_channels=out_channles,
kernel_size=3, pad=18, dilation_rate=18)
self.image_pool = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(
in_channels=in_channles, out_channels=out_channles,
kernel_size=1, stride=1, padding=0, dilation=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True))
self.final_conv = Atrous_Convolution(
input_channels=out_channles * 5, output_channels=out_channles,
kernel_size=1, pad=0, dilation_rate=1)
def forward(self, x):
x_1x1 = self.conv_1x1(x)
x_6x6 = self.conv_6x6(x)
x_12x12 = self.conv_12x12(x)
x_18x18 = self.conv_18x18(x)
img_pool_opt = self.image_pool(x)
img_pool_opt = F.interpolate(
img_pool_opt, size=x_18x18.size()[2:],
mode='bilinear', align_corners=True)
# concatination of all features
concat = torch.cat(
(x_1x1, x_6x6, x_12x12, x_18x18, img_pool_opt),
dim=1)
x_final_conv = self.final_conv(concat)
return x_final_conv
Decoder:
The encoder features are bi-linearly up-sampled by a factor of 4 and then concatenated with corresponding low-level features. 1X1 convolution is applied before concatenation so that the number of channels can be reduced. This is because the low-level features usually contain a large number of channels which may outweigh the importance of the rich encoder features. After concatenation, we apply 3X3 convolution to refine the features. The refined features are followed by another simple bi-linear up-sampling by a factor of 4.
Wrapping up the architecture:
For the backbone network we will be using the ResNet50:
class ResNet_50(nn.Module):
def __init__(self, output_layer=None):
super(ResNet_50, self).__init__()
self.pretrained = models.resnet50(pretrained=True)
self.output_layer = output_layer
self.layers = list(self.pretrained._modules.keys())
self.layer_count = 0
for l in self.layers:
if l != self.output_layer:
self.layer_count += 1
else:
break
for i in range(1, len(self.layers)-self.layer_count):
self.dummy_var = self.pretrained._modules.pop(self.layers[-i])
self.net = nn.Sequential(self.pretrained._modules)
self.pretrained = None
def forward(self, x):
x = self.net(x)
return x
class Deeplabv3Plus(nn.Module):
def __init__(self, num_classes):
super(Deeplabv3Plus, self).__init__()
self.backbone = ResNet_50(output_layer='layer3')
self.low_level_features = ResNet_50(output_layer='layer1')
self.assp = ASSP(in_channles=1024, out_channles=256)
self.conv1x1 = Atrous_Convolution(
input_channels=256, output_channels=48, kernel_size=1,
dilation_rate=1, pad=0)
self.conv_3x3 = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.classifer = nn.Conv2d(256, num_classes, 1)
def forward(self, x):
x_backbone = self.backbone(x)
x_low_level = self.low_level_features(x)
x_assp = self.assp(x_backbone)
x_assp_upsampled = F.interpolate(
x_assp, scale_factor=(4, 4),
mode='bilinear', align_corners=True)
x_conv1x1 = self.conv1x1(x_low_level)
x_cat = torch.cat([x_conv1x1, x_assp_upsampled], dim=1)
x_3x3 = self.conv_3x3(x_cat)
x_3x3_upscaled = F.interpolate(
x_3x3, scale_factor=(4, 4),
mode='bilinear', align_corners=True)
x_out = self.classifer(x_3x3_upscaled)
return x_out
Using Deeplabv3+ for Person Segmentation:
For the dateset, we will be using person segmentation dataset. It consist of images and masks of 640X640 dimension with some augmentation like channel shuffle, rotation and Horizontal-flip etc.
The dateset can be downloaded from :
Datasets and Dataloader:
import os
import torch
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
TRAIN_IMG_DIR = "data/new_data/train/image"
TRAIN_MASK_DIR = "data/new_data/train/mask"
VAL_IMG_DIR = "data/new_data/test/image"
VAL_MASK_DIR = "data/new_data/test/mask"
class PersonSegmentData(Dataset):
def __init__(self, image_dir, mask_dir, transform=None) -> None:
super(PersonSegmentData, self).__init__()
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
image_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(
self.mask_dir, self.images[index].replace(".jpg", ".png"))
image = np.array(Image.open(image_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"),
dtype=np.float32) # l -> grayscale
mask[mask == 255.0] = 1.0
if self.transform is not None:
augemantations = self.transform(image=image, mask=mask)
image = augemantations['image']
mask = augemantations['mask']
return image, mask
def get_data_loaders(
train_dir, train_mask_dir, val_dir, val_maskdir, batch_size,
train_transform, val_transform, num_workers=4, pin_memory=True):
train_ds = PersonSegmentData(
image_dir=train_dir, mask_dir=train_mask_dir,
transform=train_transform)
train_loader = DataLoader(
train_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=True,
)
val_ds = PersonSegmentData(
image_dir=val_dir,
mask_dir=val_maskdir,
transform=val_transform,
)
val_loader = DataLoader(
val_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=False,
)
return train_loader, val_loader
Hyper-parameters , train and validation loader
import os
import torch
import numpy as np
from PIL import Image
import albumentations as A
from torch.utils.data import Dataset , DataLoader
from albumentations.pytorch import ToTensorV2
from tqdm import tqdm
import torch.nn as nn
import torch.optim as optim
LEARNING_RATE = 1e-4
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 8
NUM_EPOCHS = 10
NUM_WORKERS = 4
PIN_MEMORY = True
LOAD_MODEL = False
# train transform
train_transform = A.Compose(
[
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
# validation transfroms
val_transforms = A.Compose(
[
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
train_loader , val_loader = get_data_loaders(
TRAIN_IMG_DIR,
TRAIN_MASK_DIR,
VAL_IMG_DIR,
VAL_MASK_DIR,
BATCH_SIZE,
train_transform,
val_transforms
)
Visualizing the train_loader/val_loader:
import matplotlib.pyplot as plt
import numpy as np
def show_transformed(train_loader):
batch = next(iter(train_loader))
images, labels = batch
for img , mask in zip(images,labels):
plt.figure(figsize=(11,11))
plt.subplot(1,2,1)
plt.imshow(np.transpose(img , (1,2,0)))
plt.subplot(1,2,2)
plt.imshow(mask.reshape(mask.shape[0],mask.shape[1] , 1))
show_transformed(val_loader)



Loss and Metrics:
Dice loss:
The Dice coefficient, or Dice-Sørensen coefficient, is a common metric for pixel segmentation that can also be modified to act as a loss function.

We prefer Dice Loss instead of Cross Entropy because most of the semantic segmentation comes from an unbalanced dateset. So, how most of the semantic segmentation datasets are unbalanced? Suppose you have an image of a cat and you want to segment your image as cat(foreground) vs not-cat(background). In most of these image cases you will likely see most of the pixel in an image that is not-cat (background). And on an average you may find that 70-90% of the pixel in the image corresponds to background and only 10-30% on the foreground. So, if we use CE loss the algorithm may predict most of the pixel as background even when they are not and still get low errors. But in case of Dice Loss ( function of Intersection and Union over foreground pixel ) if the model predicts all the pixel as background the intersection would be 0 this would give rise to error=1 ( maximum error as Dice loss is between 0 and 1). Hence, Dice loss gives low error as it focuses on maximizing the intersection area over foreground while minimizing the Union over foreground. For our task we will be using the BCEDice lossThis loss combines Dice loss with the standard binary cross-entropy (BCE) loss that is generally the default for segmentation models. Combining the two methods allows for some diversity in the loss, while benefiting from the stability of BCE.
class DiceBCELoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceBCELoss, self).__init__()
self.bce_losss = nn.BCEWithLogitsLoss()
def forward(self, inputs, targets, smooth=1):
BCE = self.bce_losss(inputs, targets)
inputs = torch.sigmoid(inputs)
# flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice_loss = 1 - (2.*intersection + smooth)/(
inputs.sum() + targets.sum() + smooth)
Dice_BCE = BCE + dice_loss
return Dice_BCE
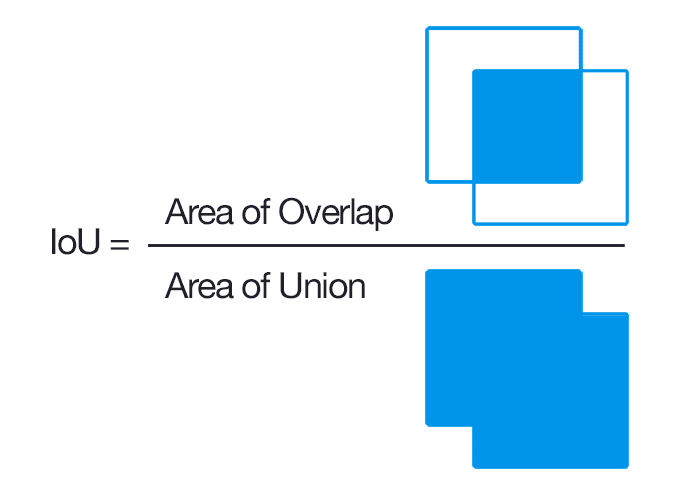
IOU:
Here we will be using the intersection over union as a performance metric for each batch in the training datasets. It is used to detect if the image is segmented right and how perfectly the image is segmented.
The IoU of a proposed set of object pixels and a set of true object pixels is calculated as:
class IOU(nn.Module):
def __init__(self, weight=None, size_average=True):
super(IOU, self).__init__()
def forward(self, inputs, targets, smooth=1):
# comment out if your model contains a sigmoid or equivalent activation layer
inputs = torch.sigmoid(inputs)
# flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
# intersection is equivalent to True Positive count
# union is the mutually inclusive area of all labels & predictions
intersection = (inputs * targets).sum()
total = (inputs + targets).sum()
union = total - intersection
IoU = (intersection + smooth)/(union + smooth)
return IoU
The Training loop:
def save_checkpoint(state, filename="resize.pth.tar"):
"""
saves checkpoint for each epoch
"""
print("=> Saving checkpoint")
torch.save(state, filename)
model = Deeplabv3Plus(num_classes=1).to(DEVICE)
loss_fn = DiceBCELoss()
iou_fn = IOU()
scaler = torch.cuda.amp.GradScaler()
optimizer = optim.Adam(model.parameters(), lr = LEARNING_RATE)
train_iou = []
train_loss = []
for epoch in range(NUM_EPOCHS):
print(f"Epoch: {epoch+1}/{NUM_EPOCHS}")
iterations = 0
iter_loss = 0.0
iter_iou = 0.0
batch_loop = tqdm(train_loader)
for batch_idx,(data,targets) in enumerate(batch_loop):
data = data.to(device = DEVICE)
targets = targets.float().unsqueeze(1).to(device=DEVICE)
with torch.cuda.amp.autocast():
predictions = model(data)
loss = loss_fn(predictions , targets)
iou = iou_fn(predictions , targets)
iter_loss += loss.item()
iter_iou += iou.item()
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
iterations += 1
batch_loop.set_postfix(diceloss = loss.item(), iou = iou.item())
train_loss.append(iter_loss / iterations)
train_iou.append(iter_iou/iterations)
print(f"Epoch: {epoch+1}/{NUM_EPOCHS}, Training loss: {round(train_loss[-1] , 3)}")
checkpoint = {
"state_dict" : model.state_dict(),
"optimizer" : optimizer.state_dict()
}
save_checkpoint(checkpoint)
num_correct = 0
num_pixels = 0
dice_score = 0
model.eval()
with torch.no_grad():
for x, y in val_loader:
x = x.to(DEVICE)
y = y.to(DEVICE).unsqueeze(1)
preds = torch.sigmoid(model(x))
preds = (preds > 0.5).float()
num_correct += (preds == y).sum()
num_pixels += torch.numel(preds)
dice_score += (2 * (preds * y).sum()) / (
(preds + y).sum() + 1e-8
)
print(
f"Got {num_correct}/{num_pixels} with acc {num_correct/num_pixels*100:.2f}"
)
print(f"Dice score: {dice_score/len(val_loader)}")
model.train()
Epoch: 1/10
100%|██████████| 2556/2556 [22:30<00:00, 1.89it/s, diceloss=0.108, iou=0.902]
Epoch: 1/10,
Training loss: 0.24
=> Saving checkpoint
Got 222509495/232243200 with acc 95.81
Dice score: 0.9310375452041626
Epoch: 2/10
100%|██████████| 2556/2556 [22:33<00:00, 1.89it/s, diceloss=0.0504, iou=0.943]
Epoch: 2/10, Training loss: 0.136
=> Saving checkpoint
Got 225145355/232243200 with acc 96.94
Dice score: 0.9528669714927673
.
.
.
.
Epoch: 10/10
100%|██████████| 2556/2556 [22:33<00:00, 1.89it/s, diceloss=0.0361, iou=0.972]
Epoch: 10/10, Training loss: 0.042
=> Saving checkpoint
Got 226039920/232243200 with acc 97.33
Dice score: 0.9583981037139893

Fig: BCEDice loss and iou over 10 epochs
Entire training process can be found here:
Testing our model:
Lets build a pipeline that blurs and removes the background from images using generated masks.
from models.deeplabv3plus import Deeplabv3Plus
import os
import torch
import torchvision
import cv2
import numpy as np
from PIL import Image
import albumentations as A
from albumentations.pytorch import ToTensorV2
from torch.utils.data import Dataset, DataLoader
from models.deeplabv3plus import Deeplabv3Plus
from copy import deepcopy
DEVICE = "cuda:0"
import warnings
warnings.filterwarnings("ignore")
def resize_with_aspect_ratio(
image, width=None, height=None, inter=cv2.INTER_AREA
):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
return cv2.resize(image, dim, interpolation=inter)
class ImageDataset(Dataset):
def __init__(self, images: np.ndarray, transform=None) -> None:
super(ImageDataset, self).__init__()
self.transform = transform
self.images = images
def __len__(self):
return len(self.images)
def __getitem__(self, index):
image = self.images[index]
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.transform is not None:
augemantations = self.transform(image=image)
image = augemantations['image']
return image
from typing import Union, Literal
class SegmentBackground():
def __init__(self, model_pth: str) -> None:
self.transforms_ = A.Compose(
[
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
A.Resize(640, 640, p=1.0),
ToTensorV2(),
],)
self.model = Deeplabv3Plus(num_classes=1).to(DEVICE)
state = torch.load(model_pth, map_location=DEVICE)
self.model.load_state_dict(state['state_dict'])
def blur_backgrond(self, image, mask):
mask = mask[0].cpu().numpy().transpose(1, 2, 0)
new_mapp = deepcopy(mask)
new_mapp[mask == 0.0] = 0
new_mapp[mask == 1.0] = 255
orig_imginal = np.array(image)
mapping_resized = cv2.resize(new_mapp,
(orig_imginal.shape[1],
orig_imginal.shape[0]),
Image.ANTIALIAS)
mapping_resized = mapping_resized.astype("uint8")
mapping_resized = cv2.GaussianBlur(mapping_resized, (0,0), sigmaX=3, sigmaY=3, borderType = cv2.BORDER_DEFAULT)
blurred = cv2.GaussianBlur(mapping_resized, (15, 15), sigmaX=0)
_, thresholded_img = cv2.threshold(
blurred, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
mapping = cv2.cvtColor(thresholded_img, cv2.COLOR_GRAY2RGB)
blurred_original_image = cv2.GaussianBlur(orig_imginal,
(151, 151), 0)
layered_image = np.where(mapping != (0, 0, 0),
orig_imginal,
blurred_original_image)
return layered_image
def remove(self,image:np.ndarray, mask: np.ndarray) -> np.ndarray:
mask = mask[0].cpu().numpy().transpose(1, 2, 0)
new_mapp = deepcopy(mask)
new_mapp[mask == 0.0] = 0
new_mapp[mask == 1.0] = 255
orig_imginal = np.array(image)
mapping_resized = cv2.resize(new_mapp,
(orig_imginal.shape[1],
orig_imginal.shape[0]),
Image.ANTIALIAS)
mapping_resized = mapping_resized.astype("uint8")
# mapping_resized = cv2.GaussianBlur(mapping_resized, (0,0), sigmaX=5, sigmaY=5, borderType = cv2.BORDER_DEFAULT)
kernel = np.ones((5, 5), np.uint8)
mapping_resized = cv2.erode(mapping_resized, kernel, iterations=1)
print(f"Mapping Resized: {mapping_resized.shape}")
# Extract the object using the mask
masked_object = cv2.bitwise_and(image, image, mask=mapping_resized)
background = np.where(mapping_resized==0,255,0).astype(np.uint8)
finalimage = cv2.cvtColor(background,cv2.COLOR_BGR2RGB)+masked_object
return finalimage
def segement(self, image:np.ndarray, operation_type:Literal["blur","remove"] )-> np.ndarray:
"""_summary_
Args:
images_list (_type_): _description_
"""
images = ImageDataset([image],
transform=self.transforms_)
loader = torch.utils.data.DataLoader(
images, batch_size=1, num_workers=1)
self.model.eval()
for img in loader:
img = img.to(device=DEVICE)
with torch.no_grad():
preds = torch.sigmoid(self.model(img))
mask = (preds > 0.5).float()
print(f"Shape of mask",mask.shape)
if operation_type == "blur":
return self.blur_backgrond(image, mask)
elif operation_type =="remove":
return self.remove(image,mask)
else:
raise ValueError("Invalid operation_type. It must be either 'blur' or 'remove'.")
import cv2
from PIL import Image
from IPython.display import display
def display_cv2(img):
# Convert the image from BGR to RGB (OpenCV uses BGR, but PIL uses RGB)
image_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Convert the OpenCV image to a PIL image
pil_image = Image.fromarray(image_rgb)
# Display the image using IPython.display
display(pil_image)
segmenter = SegmentBackground("resize.pth.tar")
test_pth = "pexels_test_2.jpg"
img = cv2.imread(test_pth)
img = resize_with_aspect_ratio(img,720)
segmented = segmenter.segement(img,operation_type="remove")
Shape of mask torch.Size([1, 1, 640, 640])
Mapping Resized: (728, 720)
display_cv2(segmented)

blurred = segmenter.segement(img,operation_type="blur")
Shape of mask torch.Size([1, 1, 640, 640])
display_cv2(blurred)

References:
- https://medium.com/swlh/review-deeplabv3-semantic-segmentation-52c00ddbf28d
- https://towardsdatascience.com/review-deeplabv3-atrous-convolution-semantic-segmentation-6d818bfd1d74
- https://www.kaggle.com/code/balraj98/deeplabv3-resnet101-for-segmentation-pytorch
Major Credit for Atrous convolution: