
In this blog, we’ll core concepts behind the LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention, diving into its use of zero-init attention and how it blends new instructional cues without compromising pre-existing knowledge. We will also cover the practical implementation of the LLaMa-Aadapter.
To facilitate understanding, let’s cover the concepts like Prompt Tuning, Prefix Tuning, and Adapter that collectively form the core of LLaMA-Adapter, empowering it with unique capabilities and efficiencies.
As we move forward, any italic text you come across indicates direct quotations from the original paper or other resources
Prompt Tuning And Prefix Tuning
Prompt Tuning
To fine-tune a pre-trained language model, you can add a customized prompt or instruction (Hard Prompting) to the input data before feeding it into the model. This prompt can be a single word, a phrase, or a sentence that directs the model to produce a particular kind of output. By doing so, you’re essentially giving the model a clear direction or guidance on what kind of response it should generate. Similarly, we can provide the model with a few examples of the desired output along with a clear indication of the task at hand. This approach allows the model to learn from the provided examples and adapt its responses accordingly. Think of it as giving the model a road map or a set of guidelines to follow, which helps it better understand what you want it to do. For example,
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction:
Create an array of length 5 which contains all even numbers between 1
and 10.
### Response:
arr = [2, 4, 6, 8, 10]
Prefix Tuning
In prefix-tuning, the model is given a few examples of text inputs accompanied by a prefix that defines the task at hand. These soft prompts serve as a means of guiding the model without explicitly stating the instructions. However, unlike hard prompts, soft prompts are not easily interpretable since they rely on complex embeddings derived from the larger model. Their advantage lies in their ability to function as a substitute for additional training data, allowing the model to discover relevant prompts for a specific task. Yet, their opacity raises questions about their transparency and interpretability.
According to the original prefix tuning paper, prefix tuning achieves comparable modeling performance to finetuning all layers while only requiring the training of 0.1% of the parameters — the experiments were based on GPT-2 models. Moreover, in many cases, prefix tuning even outperformed the finetuning of all layers, which is likely because fewer parameters are involved, which helps reduce overfitting on smaller target datasets. source
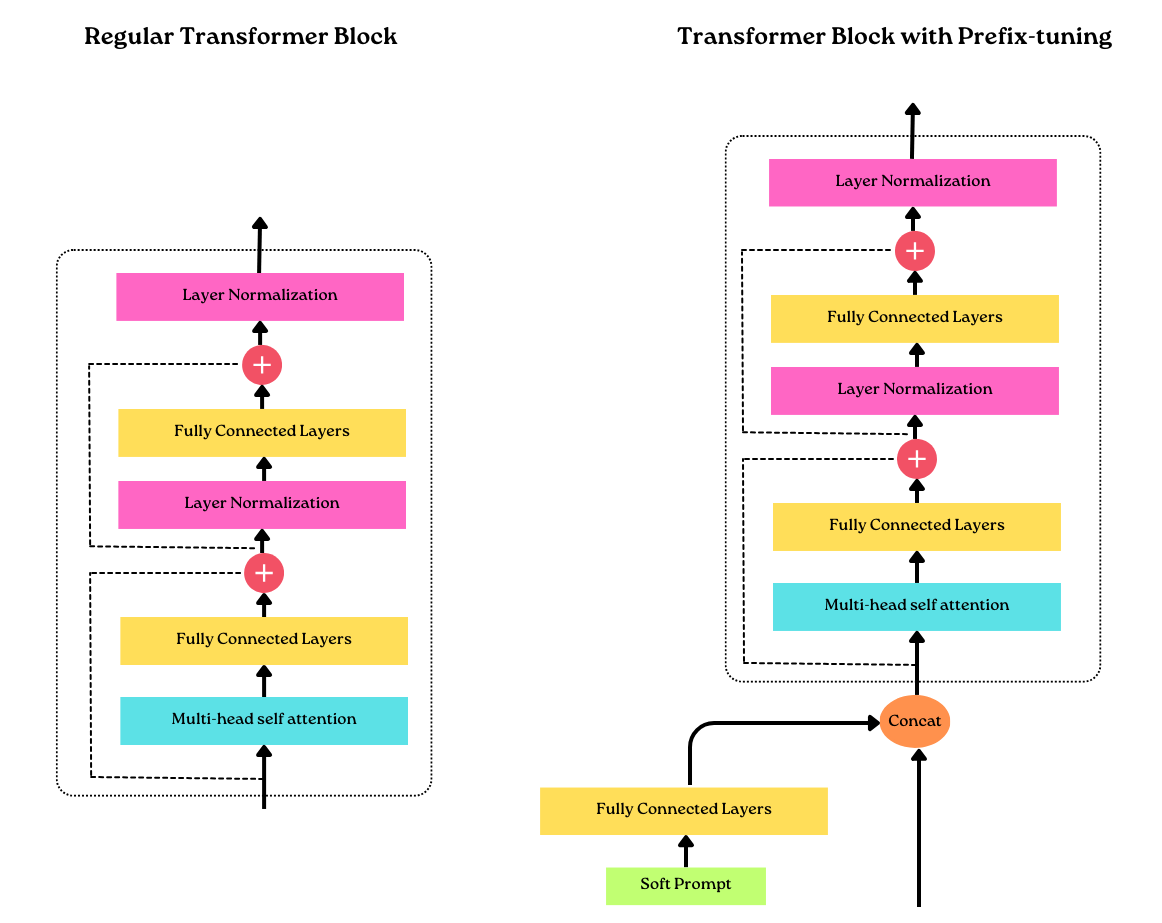
|
|---|
| Transformer with prefix tuning |
Adapter:
Both Prefix-tuning and Adapter introduce additional parameters to each transformer block. However, instead of the prefixing technique employed in prefix tuning, the adapter method diverges by incorporating adapter layers at two designated positions, as illustrated in the figure below.
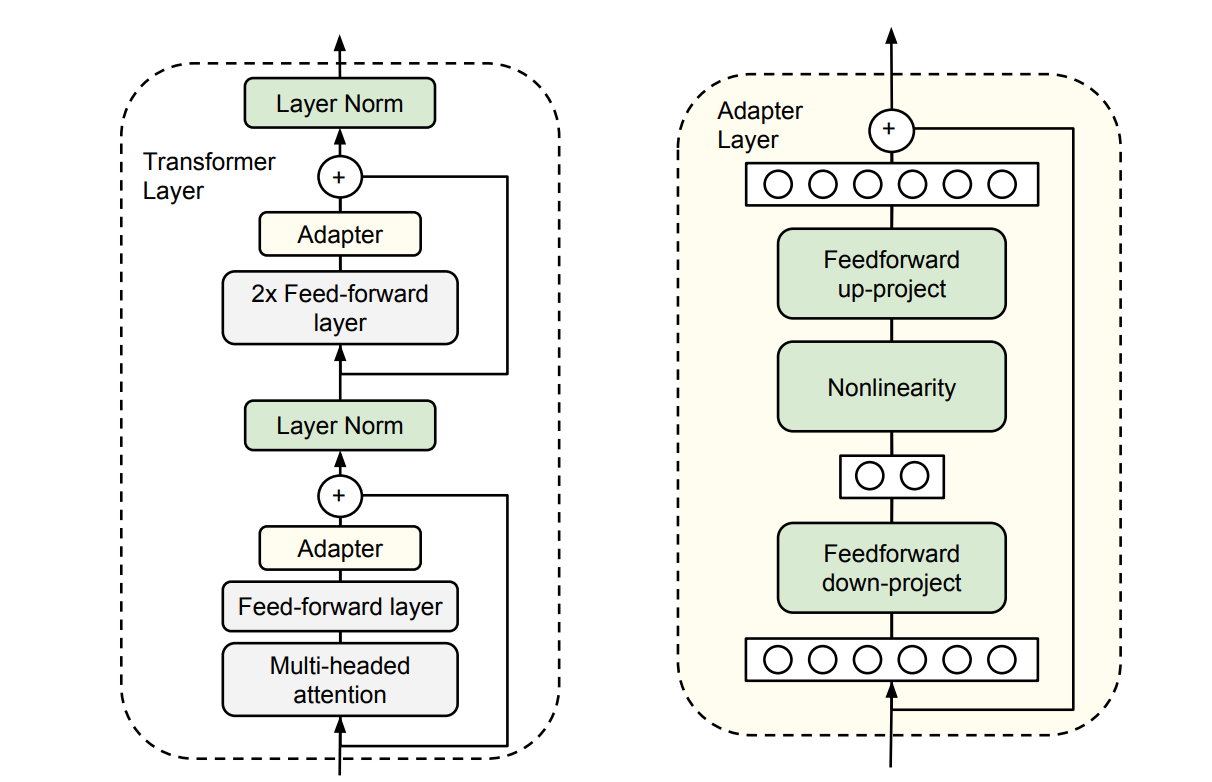
The architecture of the adapter module and its integration with the Transformer. Left: We add the adapter module twice to each Transformer layer: after the projection following multiheaded attention and after the two feed-forward layers. Right: The adapter consists of a bottleneck that contains few parameters relative to the attention and feedforward layers in the original model. The adapter also contains a skip-connection. During adapter tuning, the green layers are trained on the downstream data, this includes the adapter, the layer normalization parameters, and the final classification layer (not shown in the figure). source
According to the paper:
Adapters demonstrate their effectiveness by transferring a pre-trained BERT Transformer model to various text classification tasks, achieving near state-of-the-art performance. Importantly, they do this while adding only a minimal number of task-specific parameters per task, typically a fraction of what fine-tuning would require. For example, on the GLUE benchmark, adapters achieve nearly the same performance as full fine-tuning, by training of 3.6% of the parameters per task, compared to fine-tuning which trains 100% of the parameters for each task.
LLaMA-Adapter
The LLaMa adapter extends the ideas of prefix tuning and the original adapter method and introduce a set of adaptable prompts. These prompts are like clues that help the model better understand the instructions it’s given. They’re added to the word tokens at higher transformer layers. This approach allows the model to grasp the context of the instructions more effectively.
LLaMA-Adapter also introduces a zero-initialized attention mechanism with zero gating. This mechanism injects the new instructional cues into LLaMA, all while preserving its pre-trained knowledge. In other words, it adapts without forgetting what it already knows, making it a versatile and powerful language model.
How does it work?
Some Notations:
$N :$ layers of the transformer.
$L :$ Topmost layers of the transformer.
$M :$ length of word token
$P_l \in \mathbb{R}^{K \times C}$ : Set of learnable adaption prompts for instruction-following fine-tuning. $K$ denoting the prompt length for each layer, and $C$ equals the feature dimension of LLaMA’s transformer.
$S_{l}^{K} \in \mathbb{R}^{K \times 1}$ and $S_{l}^{M+1} \in \mathbb{R}^{(M+1) \times 1}$ denote the attention scores of $K$ adaption prompts and $M + 1$ word tokens.
LLaMA-Adapter inserts the prompts into the topmost $L$ layers of the transformer $(L ≤ N)$.
Zero-initialized Attention and Gating factor :
$S_{l}^{K} \in \mathbb{R}^{K \times 1}$ represents how much information the learnable prompt contributes which probably causes disturbance in the early training stage. To this end, we adopt a learnable gating factor, denoted as $gl$ , to adaptively control the importance of $S_l^k$ in the attention.
If the adaption prompts are randomly initialized, they might bring disturbance to the word tokens at the beginning of training, which harms the fine-tuning stability and effectiveness. Considering this, we modify the vanilla attention mechanisms at the last L transformer layers to zero-initialized attention.
Initialized by zero, $gl$ can firstly eliminate the influence of under-fitted prompts, and then increase its magnitude for providing more instruction semantics to LLaMA.
Therefore, we independently apply the soft-max functions to the two components and multiply the-first term by $gl$, formulated as: source
$$ S_{l}^{g}=\left[\operatorname{softmax}\left(S_{l}^{K}\right) \cdot g_{l} ; \quad \operatorname{softmax}\left(S_{l}^{M+1}\right)\right]^{T} $$
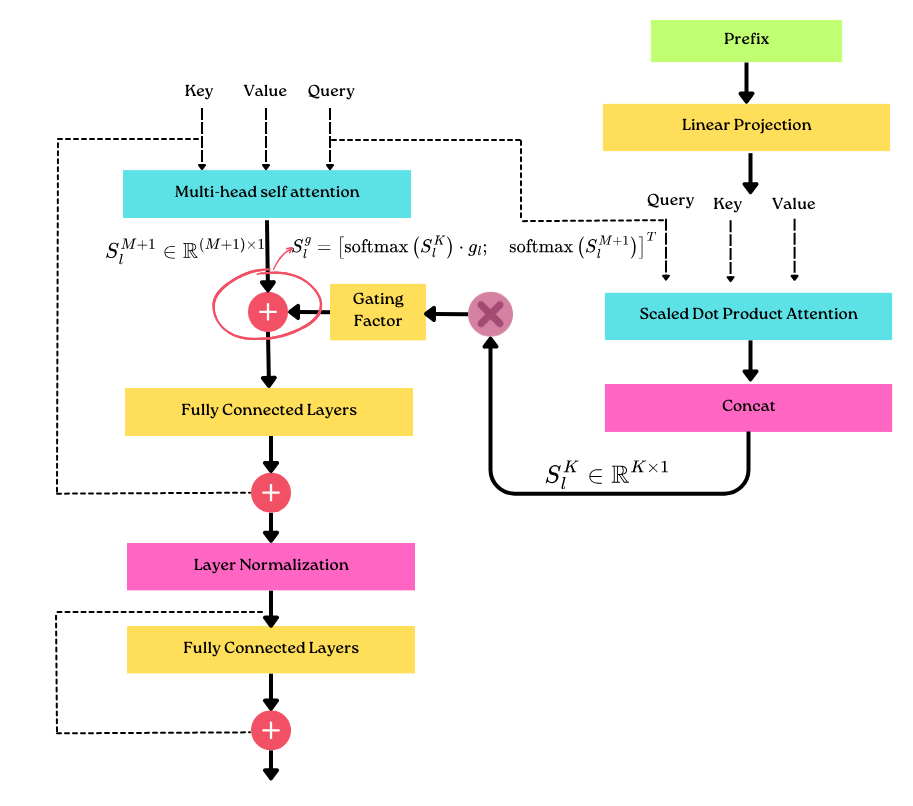
|
|---|
| Transformer with LLaMA Adapter |
LLaMA-Adapter Pseudo Code: This following pseudo-code resembles LLaMa-Adapter applied to a vanilla transformer. source
import torch
import torch.nn as nn
from torch.nn import functional as F
class LLaMAAdapter(nn.Module):
def __init__(self, prompt_length, feature_dimension, num_layers, num_head):
super().__init__()
# Learnable Adaption Prompts
self.prompt = nn.Embedding(prompt_length, feature_dimension)
# Zero Init Attention with Gating
self.gating_factors = nn.Parameter(torch.zeros(1, feature_dimension))
# k, q, v, projections
self.c_attn = nn.Linear(feature_dimension, 3 * feature_dimension, bias=False)
# Output projection
self.c_proj = nn.Linear(feature_dimension, 3 * feature_dimension , bias=False)
def forward(self, input_tokens, attention_mask):
q, k, v = self.c_attn(input_tokens).split(self.feature_dimensions, dim=2)
# Atention score for M + 1 (Word Tokens)
y = F.scaled_dot_product_attention(q, k, v, attn_mask=attention_mask, dropout_p=0.1)
_, prefix_key, prefix_value = self.c_attn(self.prompt).split(self.feature_dimensions, dim=2)
# Atention score for K (Adaption Prompt)
prefix_y = F.scaled_dot_product_attention(q, prefix_key, prefix_value, attn_mask=attention_mask, dropout_p=0.1)
# Add a learnable gating factor, to adaptively control the importance prefix_y in the attention.
y = y + self.gating_factors * prefix_y
y = self.c_proj(y)
return y
Implementing LLaMA-Adapter:
Implementing the LLaMA-Adapter requires a solid understanding of the underlying LLaMa architecture. The LLaMA-Adapter builds upon this architecture. With a thorough comprehension of LLaMa and its intricacies, implementing the LLaMA-Adapter becomes a straightforward process. You can find my in-depth blog on LLaMa. HERE.
All the codes used below are from the awesome lit-llama repo. Let’s dive into it: The CausalSelfAttention class:
The main differences lie in how the modified class potentially handles an “adaption prompt” through certain layers of the attention mechanism, which isn’t present in the original class. This is because as mentioned earlier, LLaMA-Adapter inserts the prompts into the topmost $L$ layers of the transformer $(L ≤ N)$.* Here, we are using adapter_start_layer: int = 2.
@dataclass
class LLaMAConfig(llama.LLaMAConfig):
adapter_prompt_length: int = 10
adapter_start_layer: int = 2
class CausalSelfAttention(nn.Module):
"""A modification of `lit_llama.model.CausalSelfAttention` that adds the attention
over the adaption prompt."""
def __init__(self, config: LLaMAConfig, block_idx: int) -> None:
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=False)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=False)
if block_idx >= config.adapter_start_layer:
# adapter embedding layer
self.adapter_wte = nn.Embedding(config.adapter_prompt_length, config.n_embd)
# gate for adaption
self.gating_factor = torch.nn.Parameter(torch.zeros(1))
self.n_head = config.n_head
self.n_embd = config.n_embd
self.block_size = config.block_size
self.block_idx = block_idx
self.adapter_prompt_length = config.adapter_prompt_length
self.adapter_start_layer = config.adapter_start_layer
self.rope_cache = None
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
head_size = C // self.n_head
k = k.view(B, T, self.n_head, head_size).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, head_size).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, head_size).transpose(1, 2) # (B, nh, T, hs)
if self.rope_cache is None:
# cache for future forward calls
self.rope_cache = build_rope_cache(
seq_len=self.block_size,
n_elem=self.n_embd // self.n_head,
dtype=x.dtype,
device=x.device,
)
q = apply_rope(q, self.rope_cache)
k = apply_rope(k, self.rope_cache)
# efficient attention using Flash Attention CUDA kernels
y = F.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=0.0, is_causal=True)
if self.block_idx >= self.adapter_start_layer:
prefix = self.adapter_wte.weight.reshape(1, self.adapter_prompt_length, self.n_embd)
aT = prefix.size(1)
_, ak, av = self.c_attn(prefix).split(self.n_embd, dim=2)
ak = ak.view(1, aT, self.n_head, head_size).repeat(B, 1, 1, 1).transpose(1, 2)
av = av.view(1, aT, self.n_head, head_size).repeat(B, 1, 1, 1).transpose(1, 2)
amask = torch.ones(q.shape[-2], ak.shape[-2], dtype=torch.bool, device=x.device)
ay = F.scaled_dot_product_attention(q, ak, av, attn_mask=amask, dropout_p=0.0, is_causal=False)
y = y + self.gating_factor * ay
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.c_proj(y)
return y
In the modified class, there’s an additional condition to check if the current block index (self.block_idx) is greater than or equal to the adapter_start_layer. If true, attention computations specific to the adapter are performed.
# in __init__
if block_idx >= config.adapter_start_layer:
# adapter embedding layer
self.adapter_wte = nn.Embedding(config.adapter_prompt_length, config.n_embd)
# gate for adaption
self.gating_factor = torch.nn.Parameter(torch.zeros(1))
# Forward pass
if self.block_idx >= self.adapter_start_layer:
prefix = self.adapter_wte.weight.reshape(1, self.adapter_prompt_length, self.n_embd)
aT = prefix.size(1)
_, ak, av = self.c_attn(prefix).split(self.n_embd, dim=2)
ak = ak.view(1, aT, self.n_head, head_size).repeat(B, 1, 1, 1).transpose(1, 2)
av = av.view(1, aT, self.n_head, head_size).repeat(B, 1, 1, 1).transpose(1, 2)
amask = torch.ones(q.shape[-2], ak.shape[-2], dtype=torch.bool, device=x.device)
ay = F.scaled_dot_product_attention(q, ak, av, attn_mask=amask, dropout_p=0.0, is_causal=False)
y = y + self.gating_factor * ay
If you already have a grasp of the LLaMA-Adapter pseudocode provided above, it is pretty straightforward.
The Block class:
class Block(nn.Module):
"""The implementation is identical to `lit_llama.model.Block` with the exception that
we replace the attention layer where adaption is implemented."""
def __init__(self, config: LLaMAConfig, block_idx: int) -> None:
super().__init__()
self.rms_1 = RMSNorm(config.n_embd)
self.attn = CausalSelfAttention(config, block_idx)
self.rms_2 = RMSNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x + self.attn(self.rms_1(x))
x = x + self.mlp(self.rms_2(x))
return x
Compared to the original class, the new Block passes block_idx parameter to indicate the transformer layer.
And, in the LLaMA class, we pass Block(config, i) to indicate ith transformer layer.
self.transformer = nn.ModuleDict(
dict(
wte=nn.Embedding(config.vocab_size, config.n_embd),
h=nn.ModuleList([Block(config, i) for i in range(config.n_layer)]),
ln_f=RMSNorm(config.n_embd),
)
)
This **mark_only_adapter_as_trainable method makes only the “adapter” parts of the model trainable, keeping the rest of the model non-trainable. And the adapter_state_from_state_dict extracts the “adapter” weights from the given model state dictionary so that you can save only those specific weights if needed.
def mark_only_adapter_as_trainable(model: LLaMA) -> None:
"""Sets `requires_grad=False` for all non-adapter weights."""
for name, param in model.named_parameters():
param.requires_grad = "adapter_wte" in name or "gating_factor" in name
def adapter_state_from_state_dict(state_dict: dict) -> dict:
"""Returns the model state dict with only the adapter weights for saving."""
return {name: param for name, param in state_dict.items() if "adapter_wte" in name or "gating_factor" in name}
Prepare Dateset:
For the training dataset, we will be using the alpaca dataset. The alpaca is an instruction fine-tune dataset. Here are some examples from the datasets.
{
"instruction": "Pretend you are a project manager of a construction company. Describe a time when you had to make a difficult decision.",
"input": "",
"output": "I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client\u2019s expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team\u2019s resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client\u2019s expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities."
},
{
"instruction": "Identify the odd one out.",
"input": "Twitter, Instagram, Telegram",
"output": "Telegram"
},
{
"instruction": "Explain why the following fraction is equivalent to 1/4",
"input": "4/16",
"output": "The fraction 4/16 is equivalent to 1/4 because both numerators and denominators are divisible by 4. Dividing both the top and bottom numbers by 4 yields the fraction 1/4."
},
{
To download the data and generate the Alpaca instruction tuning dataset use the following command:
python scripts/prepare_alpaca.py
This will download the data, convert to instruction fine-tune format, and tokenize the data. Before finetuning, the data will be converted to the following format:
If the prompt contains input:
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
### Instruction:
Evaluate this sentence for spelling and grammar mistakes
### Input:
He finnished his meal and left the resturant
### Response:
He finished his meal and left the restaurant.
else
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.
### Instruction:
How did Julius Caesar die?
### Response:
Julius Caesar was assassinated by a group of up to 60 conspirators, led by Gaius Cassius Longinus and Marcus Junius Brutus, in the Senate House on the Ides of March (15 March) of 44 BC.
Running the fine-tuning: source
python finetune_adapter.py
The finetuning requires at least one GPU with ~24 GB memory (GTX 3090).
You can speed up training by setting the devices variable in the script to utilize more GPUs if available.
Depending on the available GPU memory, you can also tune the micro_batch_size parameter to utilize the GPU efficiently.
For example, the following settings will let you finetune the model in under 1 hour using DeepSpeed Zero-2:
devices = 8
micro_batch_size = 8
This script will save checkpoints periodically to the folder out/.
Test the model
You can test the finetuned model with your own instructions by running:
python generate_adapter.py \\
--prompt "Recommend a movie to watch on the weekend." \\
--quantize llm.int8
Finetune on custom data. source
With only a few modifications, you can prepare and train on your own instruction dataset. Create a JSON file in which each row holds one instruction-response pair. A row has an entry for ‘instruction’, ‘input’, and ‘output’, where ‘input’ is optional and can be the empty string if the instruction doesn’t require a context. Below is an example json file:
```
[
{
"instruction": "Arrange the given numbers in ascending order.",
"input": "2, 4, 0, 8, 3",
"output": "0, 2, 3, 4, 8"
},
...
]
```
-
Make a copy of
scripts/prepare_alpaca.pyand name it what you want:cp scripts/prepare_alpaca.py scripts/prepare_mydata.py -
Modify
scripts/prepare_mydata.pyto read the JSON data file. -
Run the script to generate the preprocessed, tokenized train-val split:
python scripts/prepare_mydata.py --destination_path data/mydata/ -
Run
finetune_adapter.pyby passing in the location of your data (and optionally other parameters):python finetune_adapter.py --data_dir data/mydata/ --out_dir out/myexperiment
My fork of lit-llama can be found Here. References :
- https://arxiv.org/abs/2303.16199
- https://lightning.ai/pages/community/article/understanding-llama-adapters/
- https://github.com/Lightning-AI/lit-llama
- https://blog.wordbot.io/ai-artificial-intelligence/prompt-tuning-vs-prefix-tuning-understanding-the-differences-in-nlp-techniques/
- https://cobusgreyling.medium.com/prompt-tuning-hard-prompts-soft-prompts-49740de6c64c
- https://stackoverflow.com/questions/74710732/what-are-the-differences-between-adapter-tuning-and-prefix-tuning
- https://arxiv.org/pdf/1902.00751.pdf
- https://github.com/jianghaojun/Awesome-Parameter-Efficient-Transfer-Learning